LLM Context-Friendly Test Suite Outputs (build-output-tools-mcp)
TLDR; I developed an MCP tool to run tests/builds and routes the output to a smaller, specialized LLM for summarization to avoid flooding the main context thread of Claude Code. Check it out here: 🛠️ https://github.com/jgordley/build-output-tools-mcp
Every pytest, npm test, docker build, etc. floods Claude Code with thousands of tokens of redundant formatting and duplicate errors, burning through context that should be used for development. To address this, I developed Build Output Tools MCP, a tool that routes build/test execution and log summarization to a smaller, cheaper LLM using OpenRouter to save on context and cost while developing iteratively using agentic coding tools like Claude Code. Using this tool, I've reduced Claude Code's build and test token consumption by 85% without sacrificing debugging capability, preserving context windows for actual development instead of parsing redundant build and test formatting and duplicate errors.
Background
While developing projects locally with Claude Code, I've been keeping my increments of progress to short, testable chunks that make it as easy as possible for the LLM to get to the correct solution fast. In many cases, this involves having Claude Code run either pytest or npm run test to validate that fixes are working correctly and the package is still building.
But how much damage are these long build or test outputs doing to my Claude Code context window as a result of human output formatting? A quick look at the default pytest output shows some serious inefficiencies:
$ pytest
=========================================== test session starts ===========================================
platform darwin -- Python 3.12.1, pytest-7.4.3, pluggy-1.6.0
rootdir: /Users/jgordley/Documents/projects/build-output-tools-mcp
configfile: pytest.ini
plugins: anyio-3.7.1
collected 34 items
tests/test_build_runner.py ssssss [ 17%]
tests/test_output_storage.py ...F... [ 88%]
tests/test_safety.py .sFs [100%]
================================================ FAILURES =================================================
______________________________ TestLLMAnalyzer.test_analyzer_initialization _______________________________
self = <tests.test_llm_analyzer.TestLLMAnalyzer object at 0x107d9f080>, mock_env_vars = None
def test_analyzer_initialization(self, mock_env_vars):
"""Test LLMAnalyzer initialization with environment variables."""
analyzer = LLMAnalyzer()
> assert analyzer.api_key == "test_api_key"
E AssertionError: assert 'test_api_key_never_real' == 'test_api_key'
E - test_api_key
E + test_api_key_never_real
...
For example, formatting ==== signs contribute 40+ tokens to the output while offering very little semantic value. However, after checking some of the Claude Code logs I did see that Claude is making use of some built in option flags to keep the output concise and helpful, i.e using the short output and quiet flags:
$ python -m pytest tests/ --tb=short -q
With the quiet and short flags set, the output is definitely more consolidated. However, these outputs still suffer heavily from duplicated content. For instance, the same error may be present in a function that's used across many tests, leading to a huge increase in # of tokens without any meaningful helpfulness for Claude Code to debug the issue:
============================================ warnings summary =============================================
../../../.pyenv/versions/3.12.1/lib/python3.12/site-packages/starlette/formparsers.py:10
/Users/jgordley/.pyenv/versions/3.12.1/lib/python3.12/site-packages/starlette/formparsers.py:10: PendingDeprecationWarning: Please use `import python_multipart` instead.
import multipart
tests/test_build_runner.py:11
/Users/jgordley/Documents/projects/build-output-tools-mcp/tests/test_build_runner.py:11: PytestUnknownMarkWarning: Unknown pytest.mark.asyncio - is this a typo? You can register custom marks to avoid this warning - for details, see https://docs.pytest.org/en/stable/how-to/mark.html
@pytest.mark.asyncio
tests/test_build_runner.py:22
/Users/jgordley/Documents/projects/build-output-tools-mcp/tests/test_build_runner.py:22: PytestUnknownMarkWarning: Unknown pytest.mark.asyncio - is this a typo? You can register custom marks to avoid this warning - for details, see https://docs.pytest.org/en/stable/how-to/mark.html
@pytest.mark.asyncio
... repeats 10 more times on different lines
Each identical warning above is 95 tokens, multiplied by 10 and these duplicates are wasting nearly 1000 tokens of context.
First Attempt - pytest -llm
My first attempt at solving this was implementing a pytest flag pytest -llm that would format pytest output in a more efficient, llm-friendly way (markdown style, less formatting). However, this only led to minimal reduction in token context (~10%) which did not scale with a larger amount of errors or warnings.
| Method | Tokens | Reduction |
|---|---|---|
| Default | 1,968 | 0% |
| --tb=short -q | 1,711 | 13.1% |
| Custom --llm | 1,543 | 21.6% |
This exercise, although not a proper solution, shed light on another critical piece of the problem I was facing. Reducing formatting helps, but the main task at hand was reducing the amount of duplicate errors or errors originating from the same issue which led to a significantly larger amount of tokens in the build or test output. Then I had an idea - could I just have a smaller, cheaper LLM scan over the build and return a build summary for me with errors pointed out in a concise, token-efficient manner?
Build Output Tools MCP
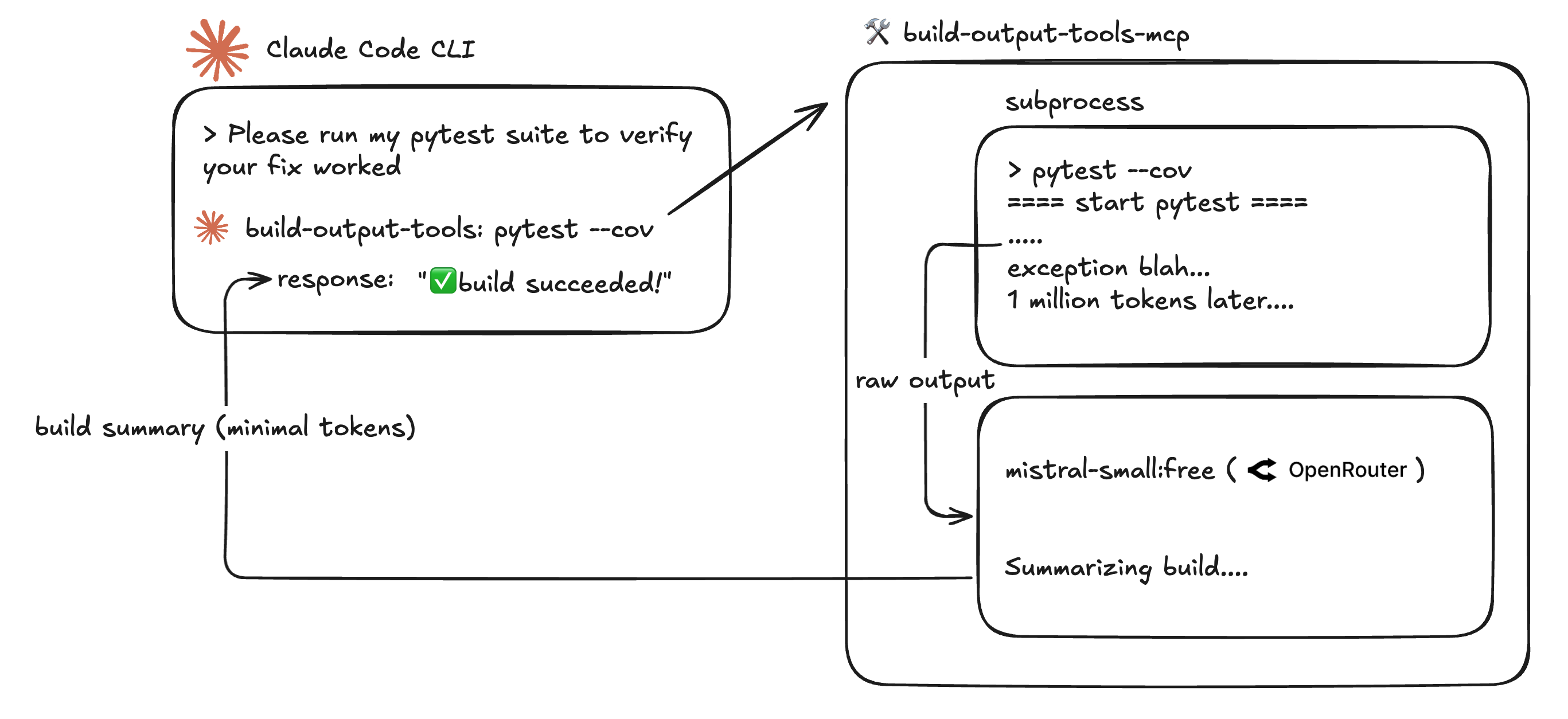
To implement this solution, I created build-output-tools-mcp. This MCP tool works by accepting an input build/run command (i.e. npm), a list of flags to run with it, and a directory to run the command in. The test or build command is then executed by a subprocess thread and the output is saved in a .txt file under a unique build_id. The raw build output is then sent to an LLM of the user's choosing through the OpenRouter API for summarization and insight recommendation. The resulting build status, summary, and build id are returned so that Claude Code can make a decision if it has enough information to debug and make fixes or optionally retrieve the raw build output from the tool using the build_id.
> code
⏺ I see you have a simple FastAPI server project for helping users
consolidate their blogs and RSS feeds. The git status shows you have
some modified files and a new constants file. How can I help you with this project?
> mcp
╭───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ Tools for build-output-tools (6 tools) │
│ │
│ ❯ 1. run_build │
│ 2. get_build_output │
│ 3. list_build_history │
│ 4. list_providers │
│ ↓ 5. list_models
In this example, running pytest in my FastAPI project resulted in a 3017 token output, largely plagued by duplicate errors involving a missed import. The below summary was only 458 tokens but contained all the relevant information that Claude Code needed to fix the issue, eliminating ~85% of the unnecessary context tokens that would have come from the raw pytest logs.
⏺ build-output-tools:run_build (MCP)(project_path:
"/Users/jgordley/Documents/projects/build-output-tools-mcp",
command: "pytest")
⎿ {
"status": "failed",
"exit_code": 1,
"command": "pytest",
"project_path": "/Users/jgordley/Documents/projects/build-output-tools-mcp",
"build_id": "1751250845_7959",
"stdout_lines": 200,
"stderr_lines": 0,
"has_output": true,
"summary": <detailed markdown summary below>
}
The summary itself (formatted):
# Summary of pytest Output
## 1. Overall Status and Key Results
**Status:** Failed (3 tests failed, 8 passed, 23 skipped)
**Total Tests:** 34 (collected)
**Failures:**
- `test_analyzer_initialization` (LLMAnalyzer API key mismatch)
- `test_list_recent_outputs` (OutputStorage command order incorrect)
- `test_environment_isolation` (Safety test detected "real" in test API key)
## 2. Important Errors or Warnings
### Assertion Errors:
- API key mismatch (`test_api_key_never_real` vs `test_api_key`)
- Incorrect command order in `list_recent_outputs` (expected `command2`, got `command0`)
- Safety test failed due to "real" substring in test API key
### Warnings:
- Multiple `PytestUnknownMarkWarning` for `@pytest.mark.asyncio` (needs plugin registration)
- `PendingDeprecationWarning` for `multipart` import
- `PytestUnhandledCoroutineWarning` (async functions skipped; requires async plugin)
## 3. Actionable Next Steps
- Fix API key initialization in `LLMAnalyzer` to match test expectations.
- Verify `OutputStorage.list_recent_outputs` ordering logic (should be reverse chronological).
- Update safety test to ensure test API keys don't contain "real".
- Register `@pytest.mark.asyncio` or install `pytest-asyncio` for async test support.
- Address deprecation warnings (e.g., replace `multipart` with `python_multipart`).
## 4. Key Metrics
- **Pass Rate:** 8/34 (23.5%)
- **Warnings:** 47 (mostly async-related)
- **Duration:** 0.32 seconds"
Storing Builds for Continuity and Context
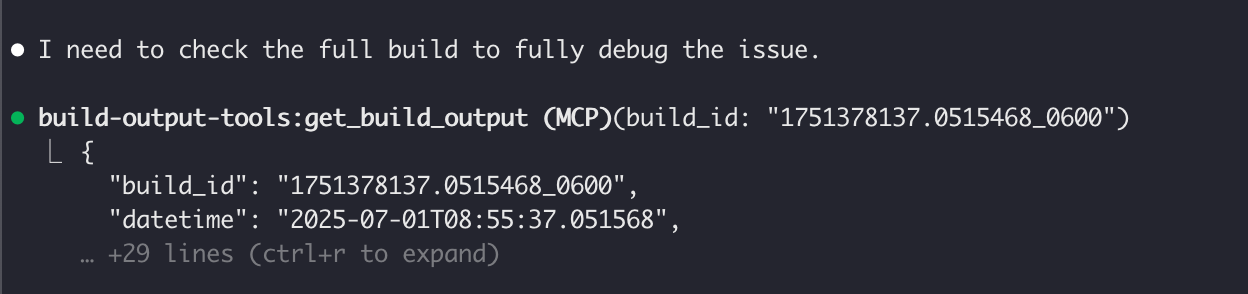
Although the summary is often all Claude Code needs to fix issues, there are still some instances where the raw build output is helpful. For instance, I ran into a couple of scenarios where Claude wanted to see the full stack trace in order to fully debug the issue. To address this, I added build tracking through an ID system where each build raw output is stored in a text file and labeled with an ID so Claude Code can retrieve the raw output as needed. This also opened up the possibility of comparing previous builds and allowing Claude Code to checkpoint build successes and failures.
Model Selection for Build Summarization
I experimented with several models and found these free OpenRouter options all work extremely well:
- mistralai/mistral-small-3.2-24b-instruct-2506:free
- deepseek/deepseek-r1-0528:free
- qwen/qwen3-32b:free
The key is that build or test output logs do not require the full reasoning power of frontier models. Although with OpenRouter you could specify a model like o3, these smaller options are perfect for this use case.
Improvements to the Tool
![]()
For the initial implementation I used OpenRouter as the LLM provider so I could experiment easily with smaller models through a unified API. However, like many other MCP tools out there that do some LLM routing it would be much better to support other provider APIs like OpenAI, Anthropic, or Google.
Additionally, there are basic safety checks in place to ensure that builds or tests are not executing any malicious code. My first implementation just had two inputs, a directory and a command, that would be executed using the Python subprocess library. Obviously this poses an extreme security risk, so I implemented some basic safeguards such as validation of commands against an allowlist (just npm and pytest to start) and restricts execution to the specified project directory to prevent path traversal attacks. There are definitely more scenarios like this that need to be accounted for before I would be comfortable using this in a production environment, as with any code execution libraries, sandboxed or other.
Lastly, I would like to spend time creating a proper evaluation suite for this tool. This would help answer questions like:
- How often does Claude need to take a step further and check the raw build logs?
- How many tokens are saved on average?
- Can we optimize the prompt to provide better summaries and reduce the % of time Claude needs the raw builds?
Conclusion
This approach builds on LLM routing concepts but applies them specifically to build output processing rather than traditional query routing as seen in projects like RouteLLM or AWS Prompt Routing. A more comparable approach would be a multi-agent workflow where there is a sub-agent specifically designated for running and summarizing builds and tests. Although a viable approach, it makes the process unnecessarily complex by introducing another decision step in the process, when a tool to 1. Run the build, 2. Summarize it, is extremely straightforward and easy for Claude to invoke.
Investigating build outputs and developing an MCP server from scratch taught me a lot about how Claude Code, MCP, and test frameworks work under the hood. This tool has already proved to be very valuable in my own day-to-day development. Please check out the repo and add any issues, feature requests, or ideas you have there so we can continue to make this a useful tool for other developers.
🛠️ Build Tools MCP - https://github.com/jgordley/build-output-tools-mcp
Thanks for reading!
Follow me on X for post updates and more.
To cite this post, please use:
Gordley, Jack. (Jul 2025). LLM Context-Friendly Test Suite Outputs. gordles.io. https://gordles.io/blog/llm-friendly-test-suite-outputs-pytest-llm.